使用教程
目前DuRT具有实时语音识别、文件转录、文本处理、字幕编辑、结果保存等功能。
下面简单介绍如何使用DuRT,包括使用前的注意事项和DuRT的主要功能。
实时语音识别
效果图如下:
点击展开图片
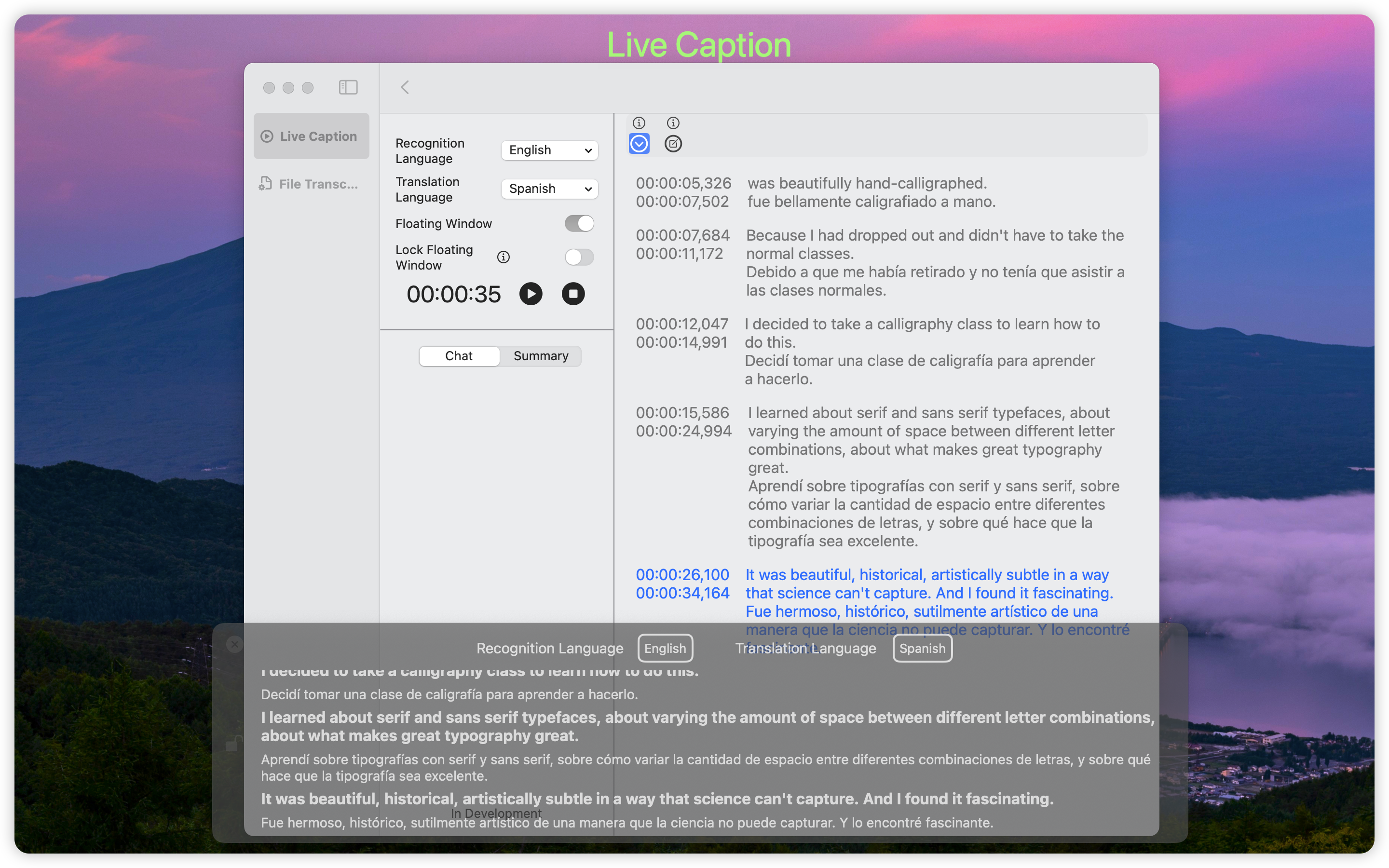
DuRT目前支持两种实时语音识别,Apple语音识别和Whisper识别。
| 识别方式 | Apple | Whisper |
|---|---|---|
| 识别效果 | 好 | 好 |
| 下载模型 | 不需要下载模型 | Whisper模型 |
| 标点符号 | 支持 | 支持 |
| 识别速度 | 实时 | 近乎实时 |
| 支持语言 | 有限 | 30+ |
| 识别过程中切换语言 | 不支持 | 支持 |
| 仅在本地运行 | 是 | 是 |
Apple语音识别
Apple识别使用macos系统内置的语音识别服务。
该语音识别是实时将语音识别成文本。
缺点是支持语言有限。 需要在设置界面,下载语言包来得到所支持的语言。
Whisper识别
DuRT通过设计Whisper识别,将Whisper语音识别做成近乎实时的语音识别。
优点是支持几十种语言,并且可以无缝识别一个视频中不同的语种。
缺点是需要下载和运行模型、会有2-3秒的延迟。
文件转录
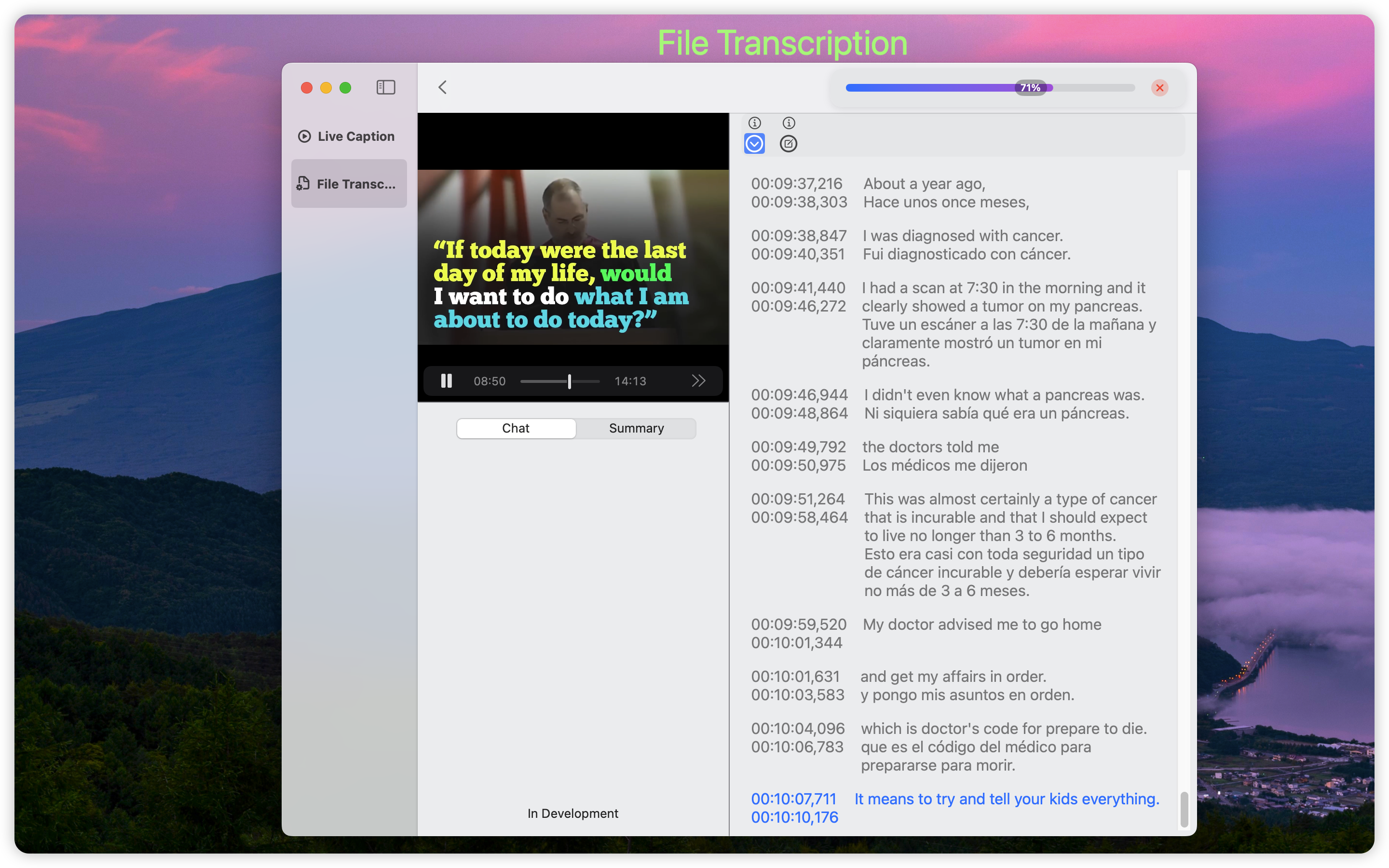
在文本转录界面,用户可以通过选择或者拖拽的方式,来选择音视频文件。
文件转录仅支持Whisper语音识别来得到识别结果。
效果图如下:
点击展开图片
文本处理
文本处理服务,借助大模型,实现任何想要的效果,比如翻译、润色、回答问题等等。
在前面实时语音识别和文件转录,都可以加入文本处理服务,来得到对应的结果,显示和保存。
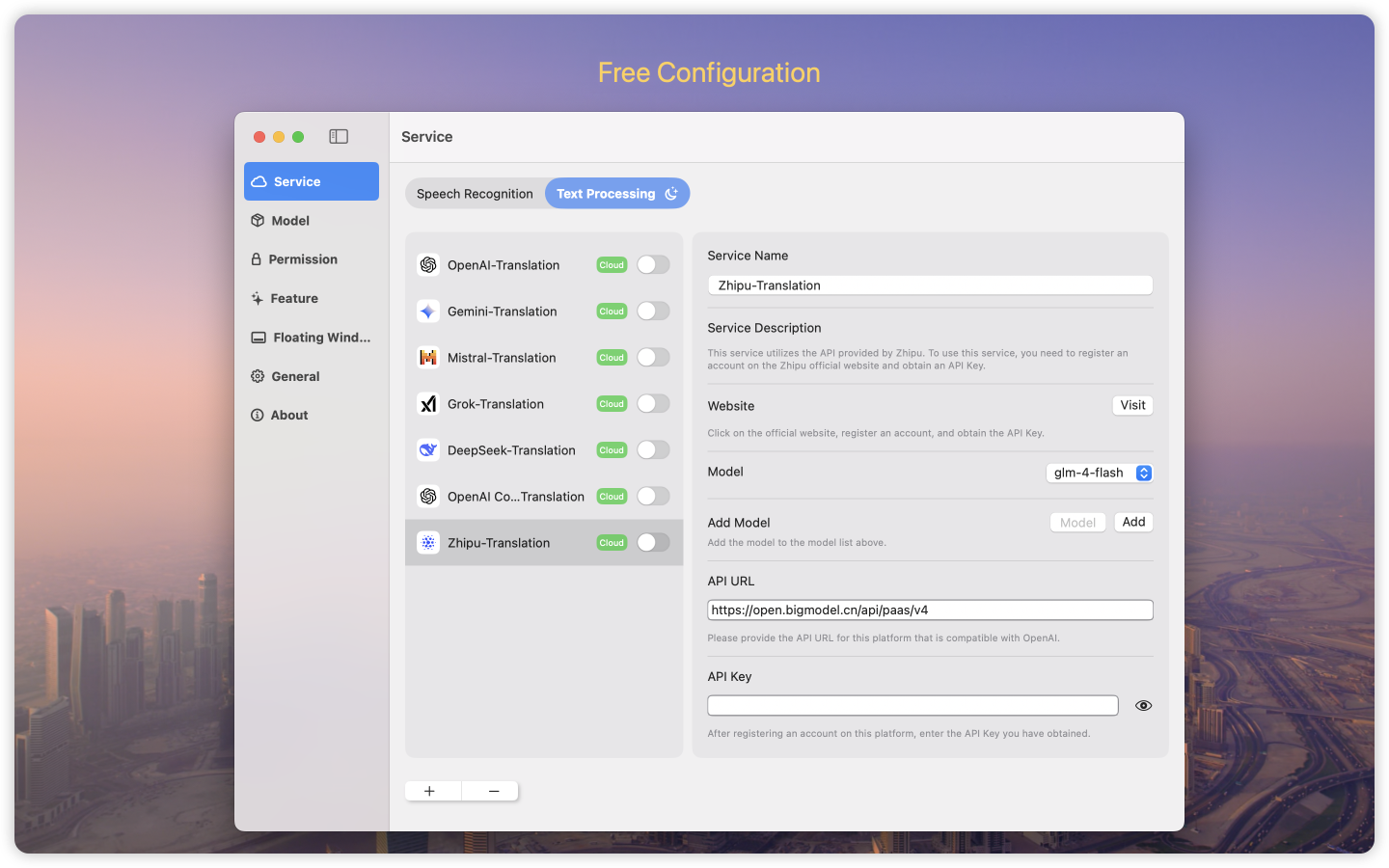
服务配置
在服务配置界面,用户可以管理语音服务和文本处理服务。
效果图如下
点击展开图片
权限申请
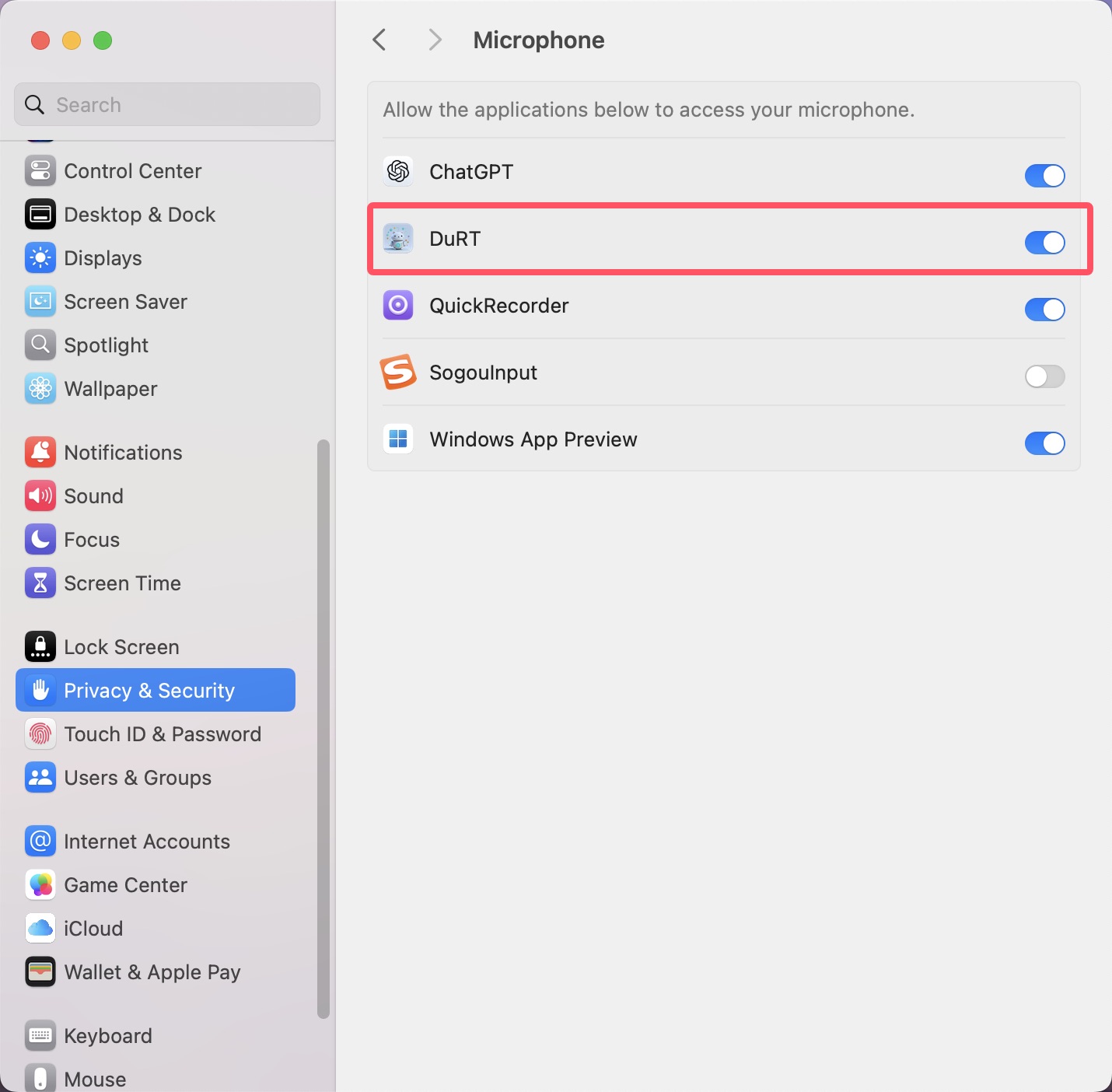
在使用语音识别时,需要首先设置权限。目前DuRT支持识别设备内语音和麦克风语音。
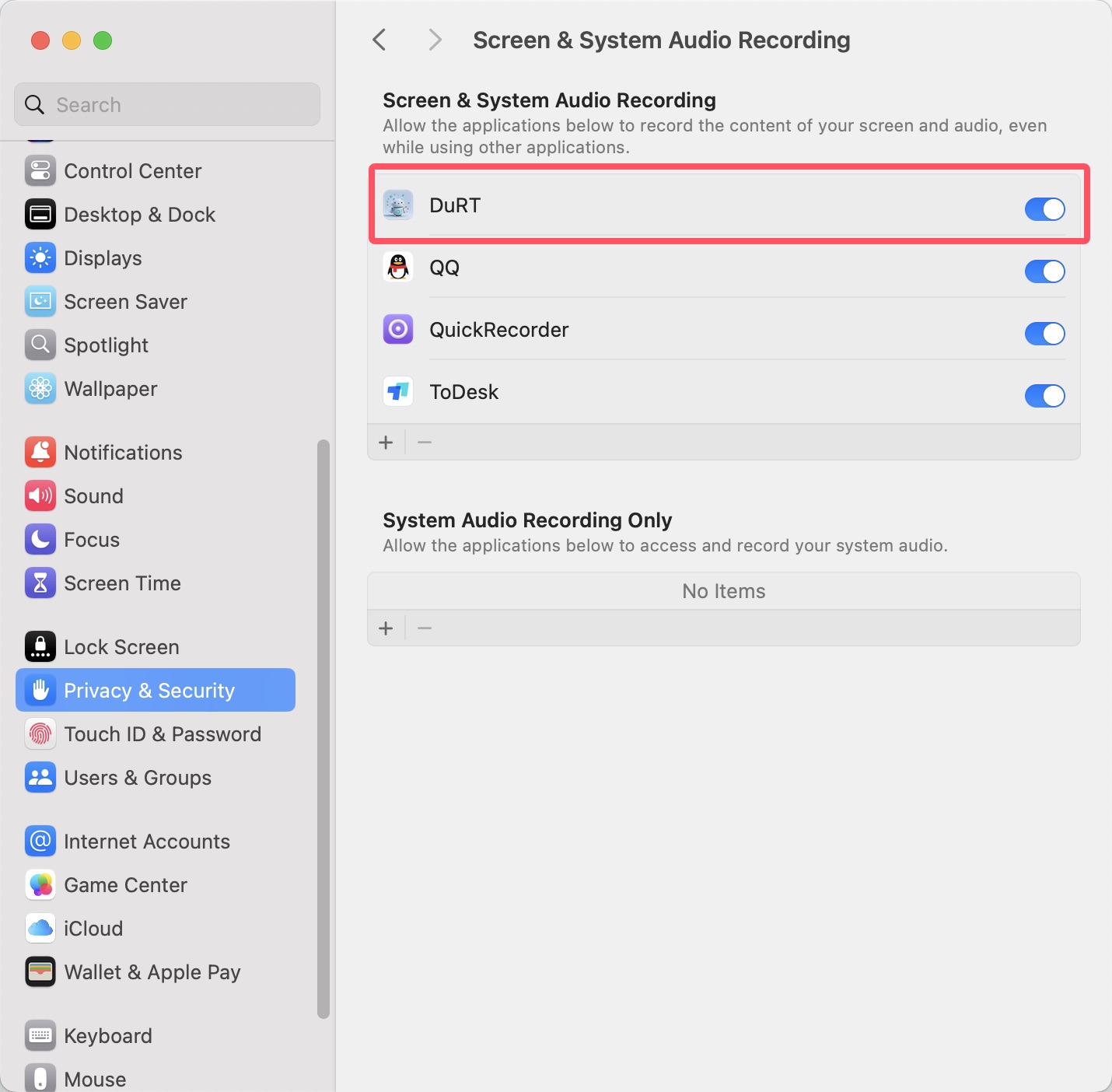
对于识别设备内音频需要录屏与系统录音权限,需要在设置>隐私与安全>录屏与系统录音,中允许DuRT使用录屏与系统录音。 如下图:
点击展开图片
对于识别麦克风语音需要麦克风权限,需要在设置>隐私与安全>麦克风,中允许DuRT访问麦克风。 如下图:
点击展开图片
保存录音、识别结果、翻译结果需要选择某个目录作为存放的位置,需要在DuRT内的设置页面,设置保存目录。
同时防止权限滥用, DuRT只会在识别运行时,使用录屏或者麦克风权限。
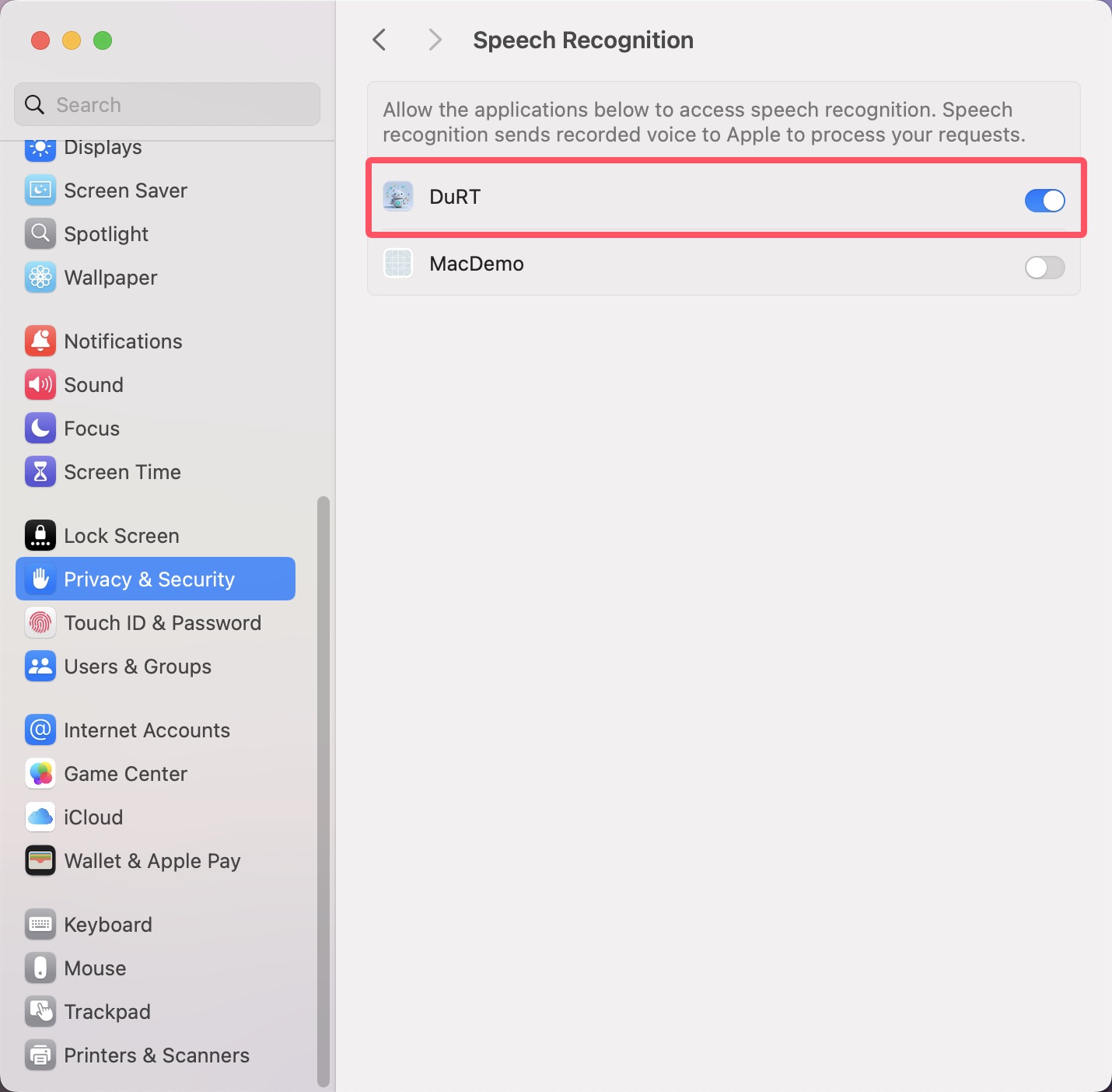
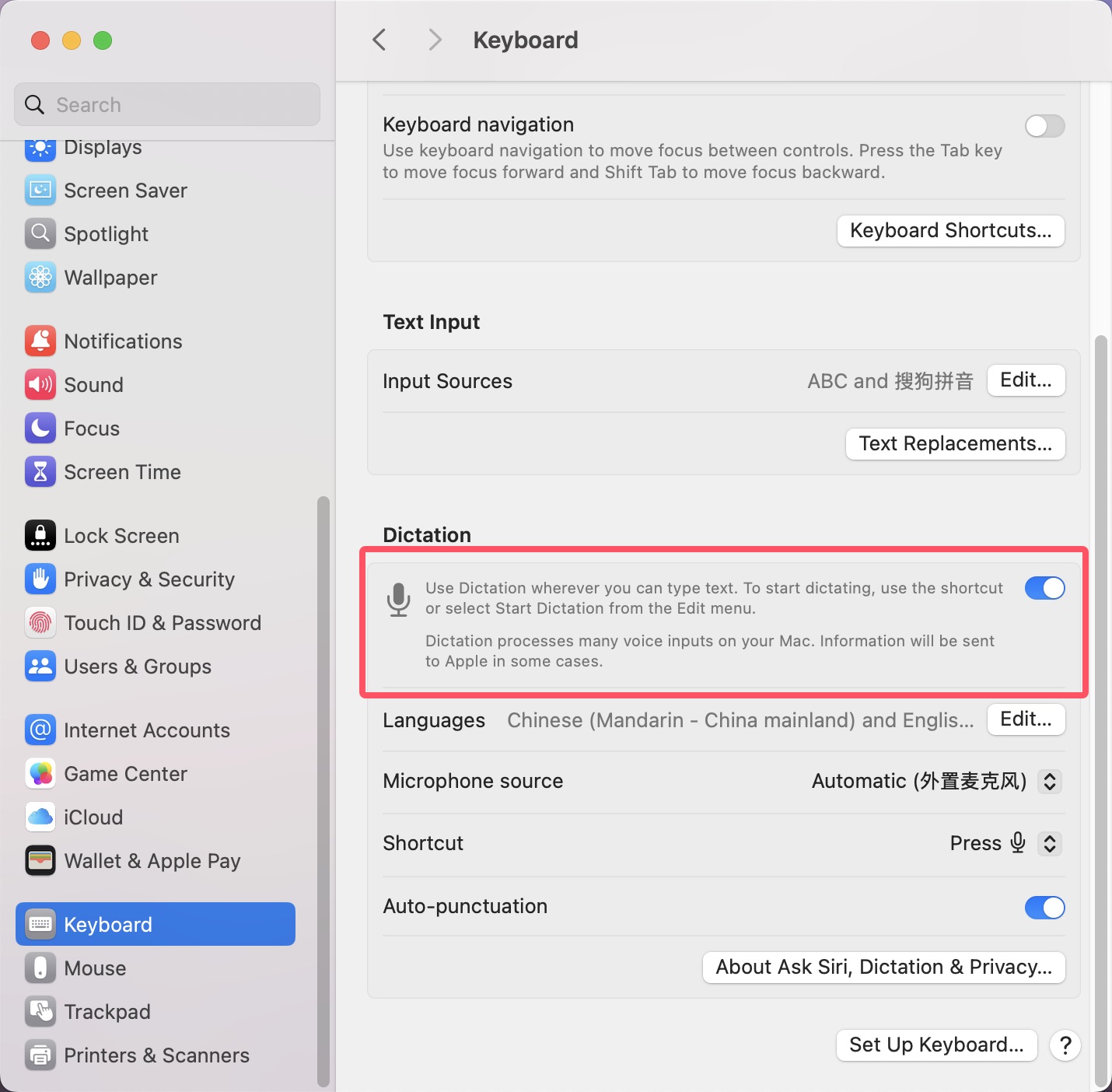
由于Apple语音识别使用的是MacOS系统中的功能。 除了上面两个录屏和麦克风权限外,还需要申请两个权限。
允许语音识别,在隐私与安全性 > 语音识别 ,允许DuRT使用。 如下图:
点击展开图片
启用键盘听写, 将设置 > 键盘 > 听写 打开。 如下图:
点击展开图片
内存占用情况
Whisper语音识别需要下载对应的Whisper模型,在运行时,所需要内存大约是模型大小的两倍。
模型详情
Whisper模型, 按照大小依次分为tiny,small,base,medium,large,和turbo。
一般来说越大的模型,识别准确度越好。
Whisper模型支持下面这些语言: 阿拉伯语、保加利亚语、加泰罗尼亚语、中文、克罗地亚语、捷克语、丹麦语、荷兰语、英语、芬兰语、法语、加利西亚语、德语、希腊语、意大利语、日语、韩语、马其顿语、波兰语、葡萄牙语、罗马尼亚语、俄语、斯洛伐克语、西班牙语、瑞典语、泰米尔语、泰语、土耳其语、乌克兰语、乌尔都语、越南语。
推荐使用的是whisper-large-v3-turbo模型。
下载Whisper模型,请查阅模型下载。