User Guide
DuRT currently offers real-time speech recognition, file transcription, text processing, subtitle editing, result saving and other features.
This guide provides a brief introduction to using DuRT, including pre-use considerations and explanations of its main functionalities.
Real-time Speech Recognition
Preview:
Click to view image
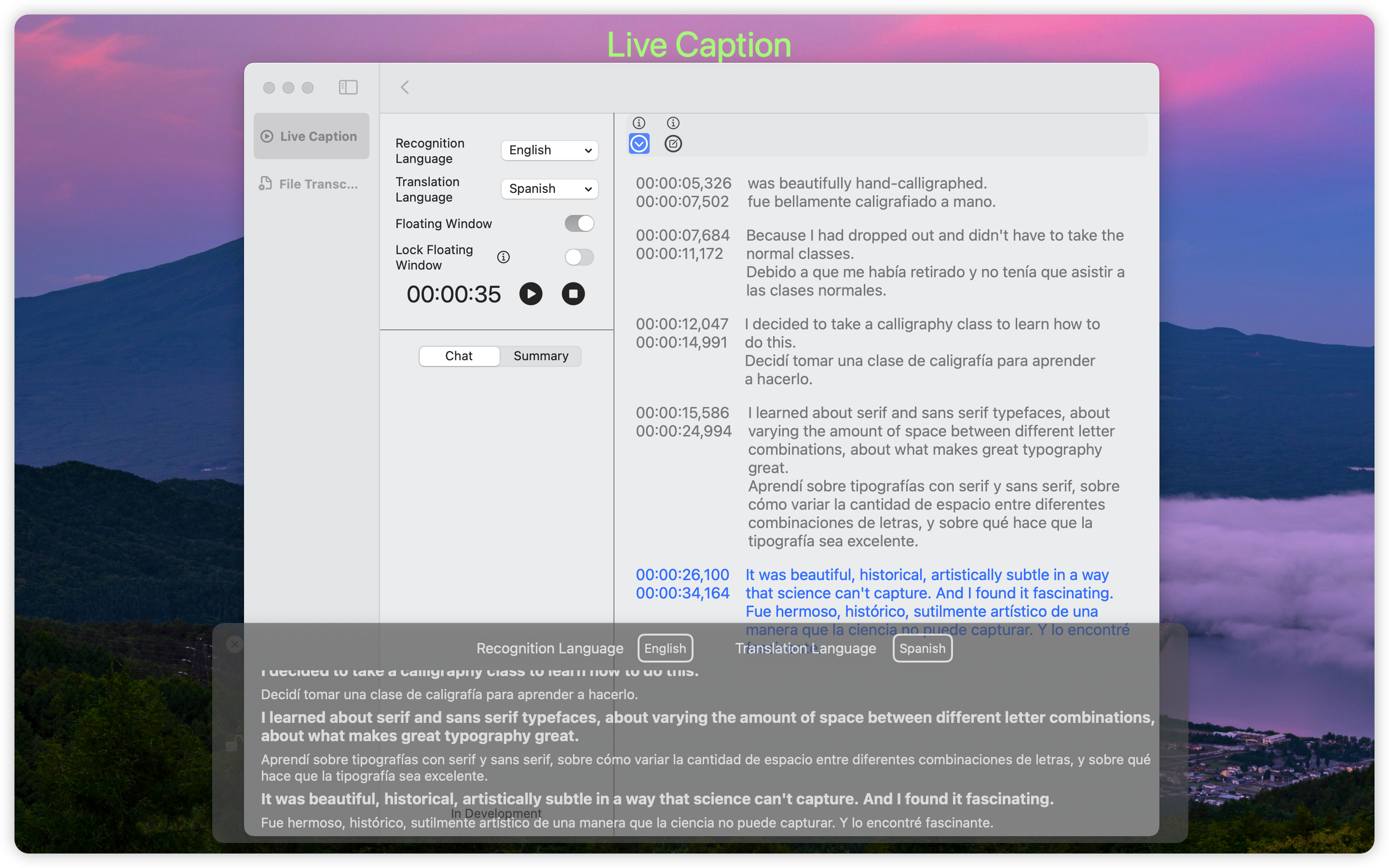
DuRT currently supports two real-time speech recognition methods: Apple Speech Recognition and Whisper Recognition.
| Feature | Apple | Whisper |
|---|---|---|
| Quality | Good | Good |
| Model Download | Not needed | Required |
| Punctuation | Supported | Supported |
| Speed | Real-time | Near real-time |
| Supported Languages | Limited | 30+ |
| Language Switching Mid-recognition | Not supported | Supported |
| Local-only Operation | Yes | Yes |
Apple Speech Recognition
Apple Recognition utilizes macOS's built-in speech recognition service.
This method provides real-time speech-to-text conversion. The main limitation is restricted language support. Users need to download language packs in system settings to access supported languages.
Whisper Recognition
DuRT implements Whisper Recognition to achieve near real-time speech recognition.
Advantages include support for dozens of languages and seamless recognition of multiple languages within a single video. The tradeoffs are model download requirements and a 2-3 second processing delay.
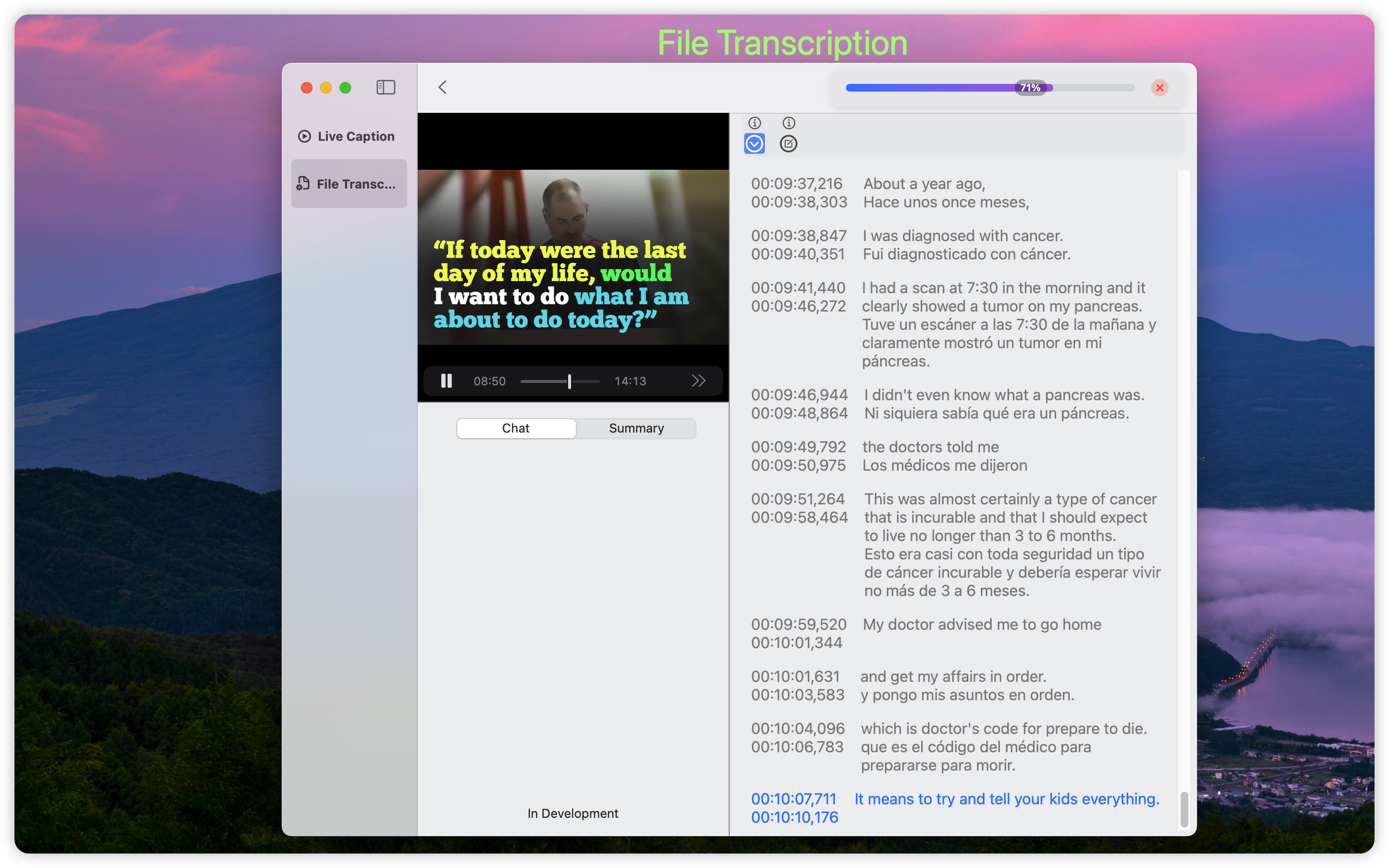
File Transcription
In the transcription interface, users can select audio/video files through file selection or drag-and-drop operations.
File Transcription exclusively uses Whisper speech recognition technology.
Preview:
Click to view image
Text Processing
The text processing service leverages large language models to achieve various effects including translation, text polishing, Q&A, etc.
Both real-time recognition and file transcription results can be processed through this service for enhanced output display and saving.
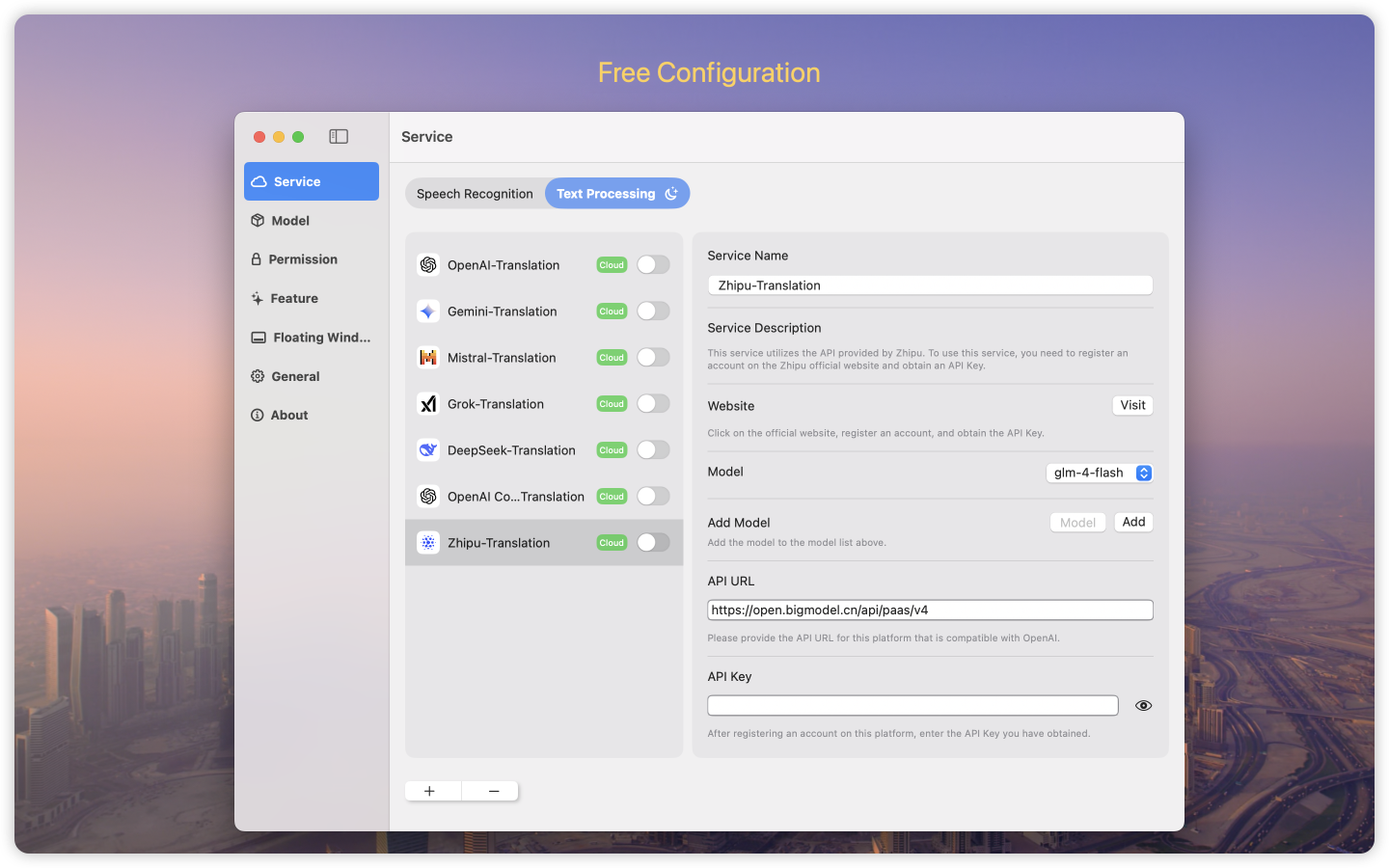
Service Configuration
In the service configuration interface, users can manage speech services and text processing services.
Preview:
Click to expand image
Permission Requirements
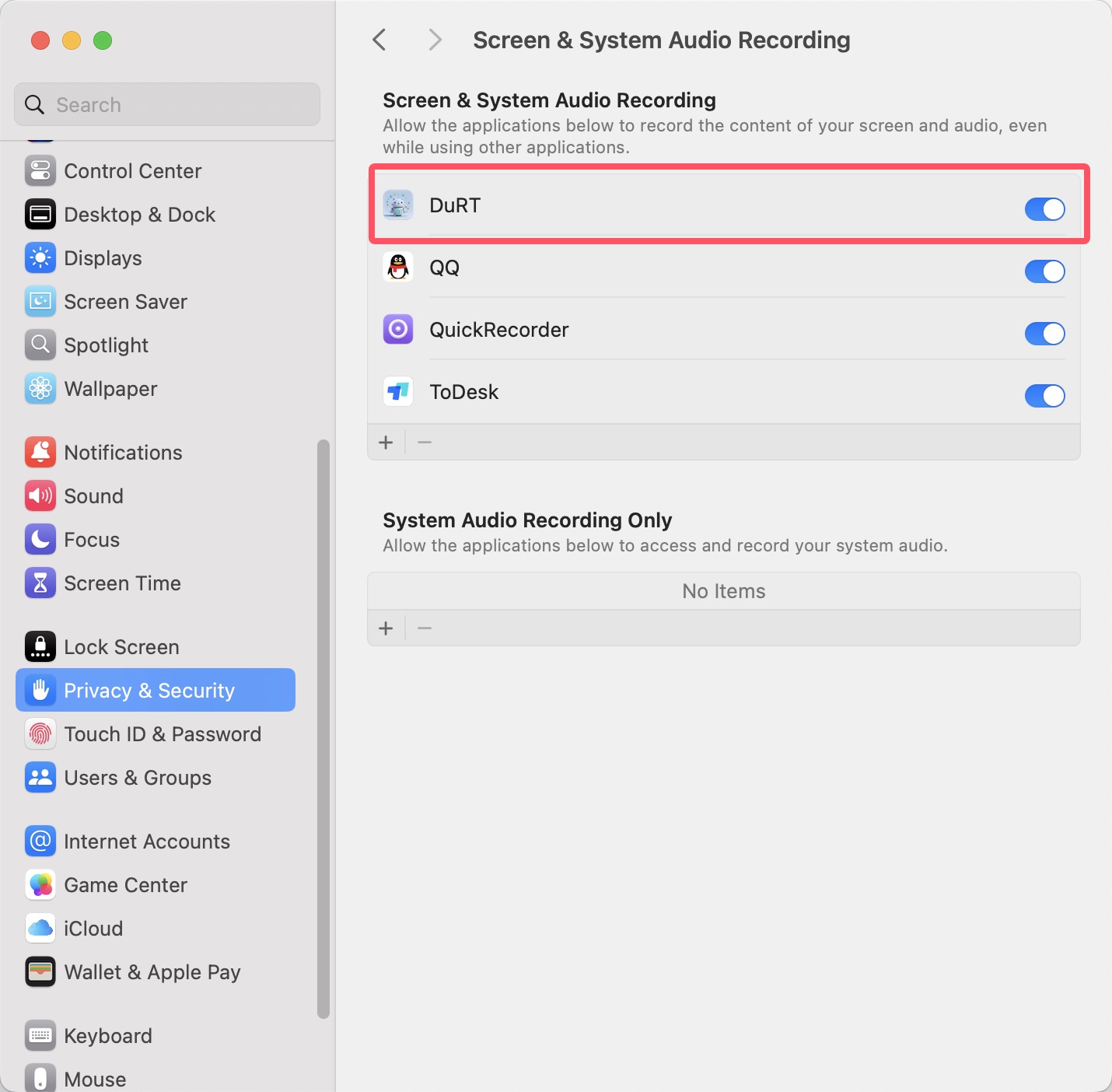
Speech recognition requires system permissions. DuRT supports both system audio capture and microphone input.
System Audio Recording requires Screen Recording & System Audio permissions: System Settings > Privacy & Security > Screen Recording & System Audio > Enable DuRT
Click to expand image
Microphone Input requires Microphone permission: System Settings > Privacy & Security > Microphone > Enable DuRT
Click to expand image
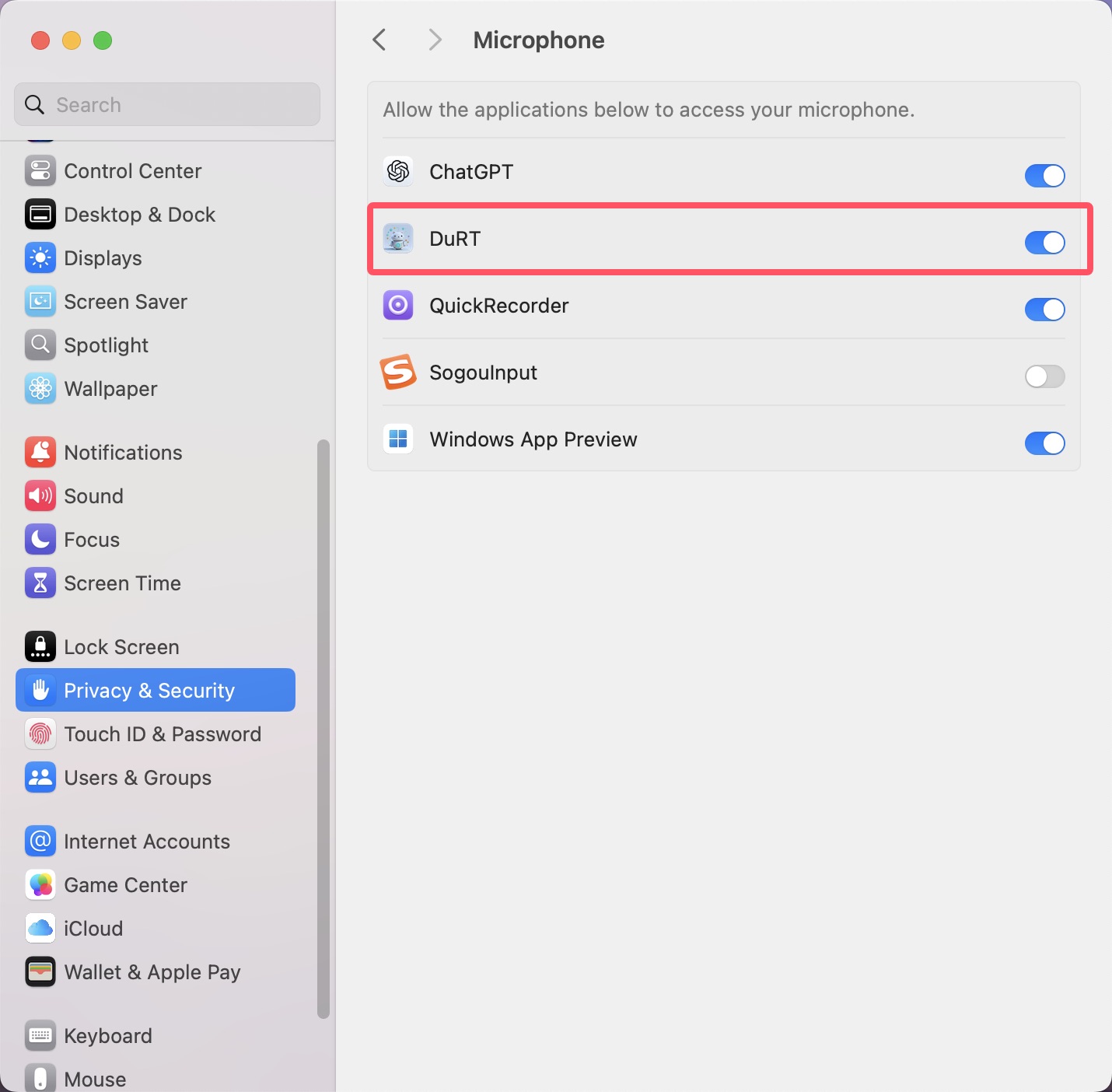
To save recordings and processing results, users need to specify a storage directory in DuRT's settings.
Security Note: DuRT only accesses recording permissions during active recognition processes.
Additional Requirements for Apple Recognition
Two additional permissions are required for Apple Speech Recognition:
- Enable Speech Recognition: System Settings > Privacy & Security > Speech Recognition > Enable DuRT
Click to expand image
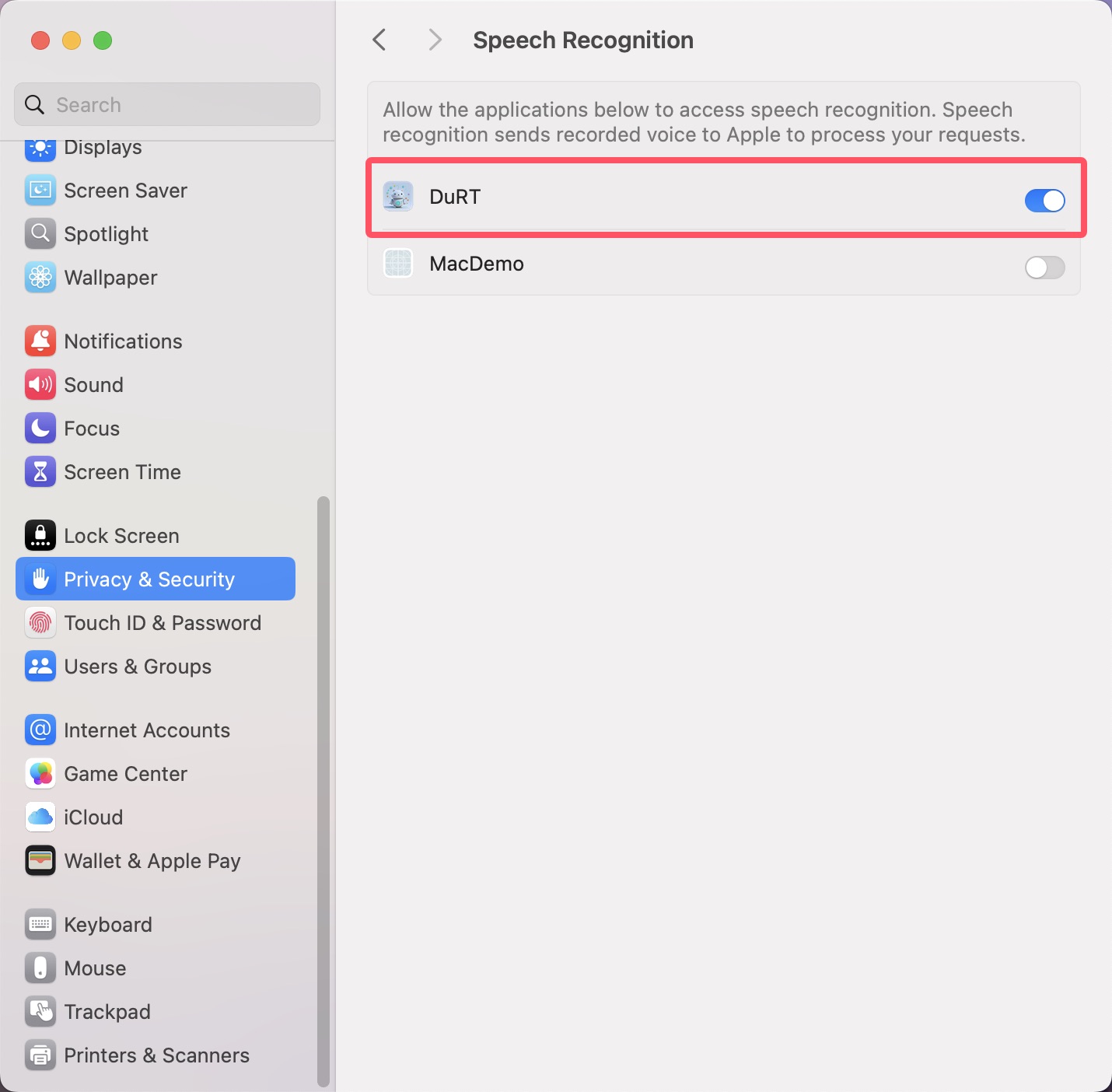
- Enable Keyboard Dictation: System Settings > Keyboard > Dictation > Turn On
Click to expand image
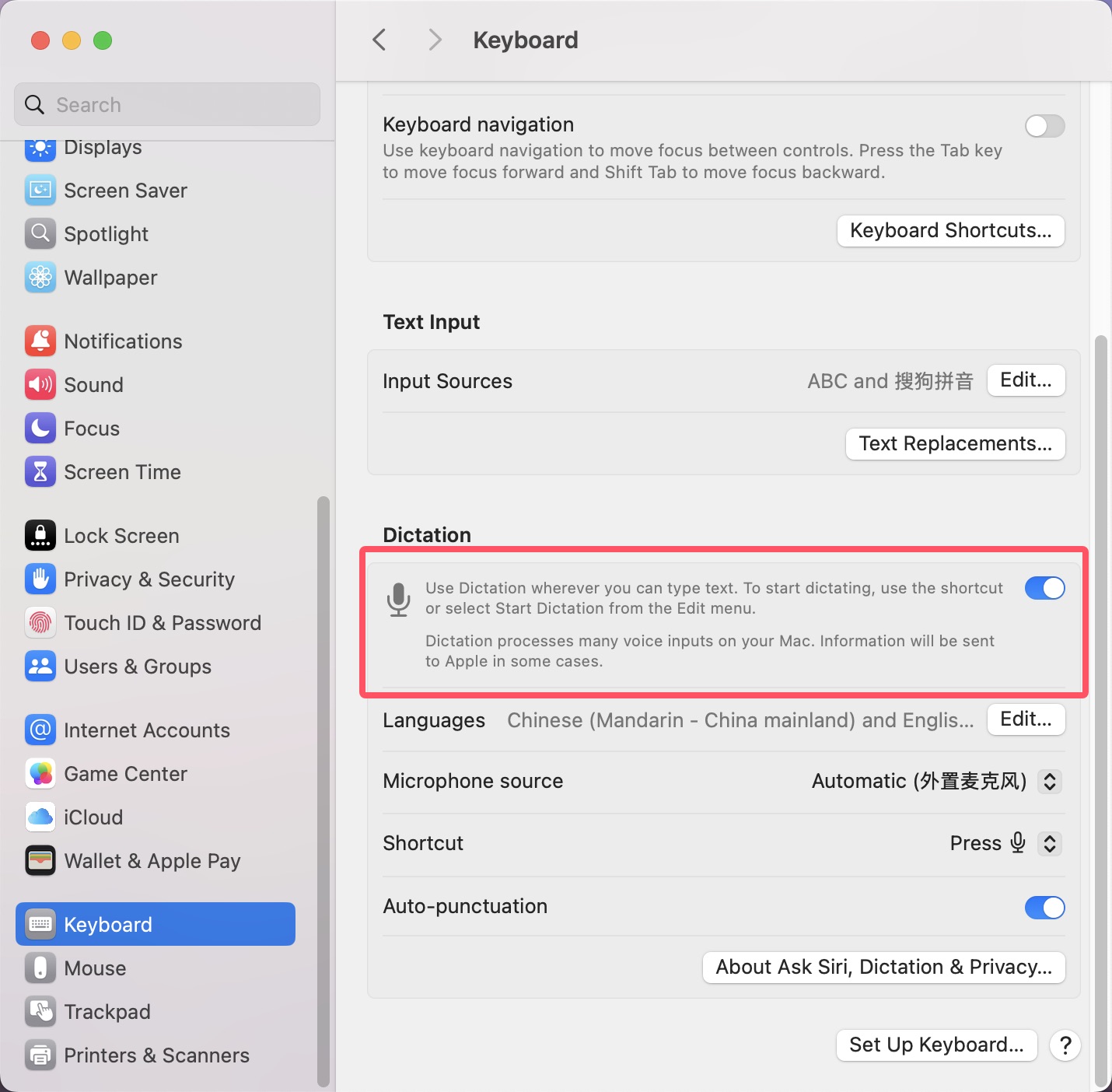
Memory Requirements
Whisper recognition requires memory allocation approximately twice the size of the loaded model.
Model Details
Whisper models are available in different sizes: tiny, small, base, medium, large, and turbo. Larger models generally provide better accuracy.
Supported languages include: Arabic, Bulgarian, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Finnish, French, Galician, German, Greek, Italian, Japanese, Korean, Macedonian, Polish, Portuguese, Romanian, Russian, Slovak, Spanish, Swedish, Tamil, Thai, Turkish, Ukrainian, Urdu, Vietnamese.
We recommend using the whisper-large-v3-turbo model.
For model downloads, see Model Download Guide.